Você sabia que com Python é possível prever o futuro dos seus dados? Por meio da análise preditiva, você consegue identificar padrões e tendências, o que pode resultar em decisões mais estratégicas e informadas. Esse tipo de análise é cada vez mais utilizado em diversas áreas, como marketing, finanças, saúde e vendas, ajudando empresas e profissionais a tomarem decisões baseadas em dados.
Neste artigo, vamos explorar como utilizar regressão, classificação e clustering para criar modelos preditivos poderosos com Python. Se você quer aprender mais e aplicar essas técnicas de maneira mais aprofundada, confira o curso Análise de Dados com Python, com inscrições até 10/11!
O que é análise preditiva e como Python pode ajudar?
A análise preditiva é um campo da ciência de dados que utiliza modelos estatísticos, algoritmos e técnicas de machine learning para prever resultados futuros com base em dados passados. Ao identificar padrões nos dados históricos, você consegue projetar cenários futuros. Usando Python, ferramentas poderosas como NumPy e Pandas tornam o processo de modelagem de dados mais acessível e eficiente. Esses recursos oferecem algoritmos de regressão, classificação e clustering, que permitem que você aborde uma variedade de problemas analíticos.
Fontes como a Scikit-learn documentation e KDnuggets ilustram a importância da Python na análise preditiva, dado o seu poder e flexibilidade. Além disso, Python é uma linguagem de código aberto com uma comunidade ativa, o que significa que sempre há novos recursos e melhorias sendo implementados.
Como a regressão com Python pode prever resultados?
Quando se trata de prever valores contínuos, como o preço de uma casa ou a temperatura futura, a regressão é uma técnica crucial. Ela tenta modelar a relação entre variáveis independentes e dependentes, permitindo prever um valor contínuo.
Com Python, você pode facilmente treinar um modelo de regressão linear e fazer previsões com base em dados de entrada. Veja o exemplo a seguir, onde usamos dados sobre imóveis para prever o preço de venda:
Este código é simples, mas pode ser expandido para problemas mais complexos, como previsão de demanda de produtos, análise de vendas ou até mesmo comportamento do consumidor.
A regressão também pode ser expandida para modelos mais sofisticados, como regressão polinomial ou regressão logística (para classificação binária), dependendo das necessidades do seu projeto.
Classificação com Python: separando os dados em categorias
Se o seu objetivo for classificar dados, como distinguir entre spam e não-spam ou prever se um cliente fará uma compra ou não, a técnica de classificação é a ideal. A classificação ajuda a atribuir rótulos a dados de entrada com base em exemplos anteriores. A técnica é amplamente utilizada em áreas como análise de risco de crédito, diagnóstico médico e detecção de fraudes.
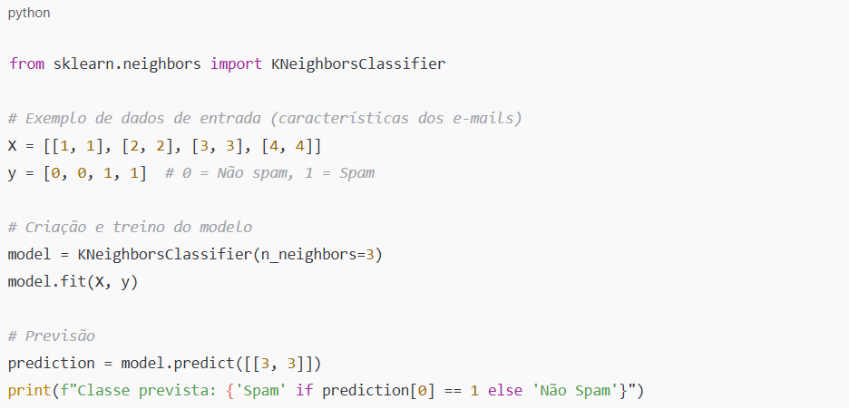
Python oferece várias bibliotecas para implementar algoritmos de classificação, como o k-vizinhos mais próximos (KNN) e máquinas de vetor de suporte (SVM). Veja o exemplo de como implementar o algoritmo KNN em Python:
Com a classificação, você pode segmentar dados em grupos úteis. Isso é especialmente valioso para marketing, onde se pode identificar grupos de clientes com maior propensão a comprar produtos específicos, ou para previsão de churn, onde você consegue prever quais clientes estão propensos a cancelar seus serviços.
Clustering: identificando padrões com Python
O clustering é uma técnica de aprendizado não supervisionado que agrupa dados semelhantes. Ao contrário da regressão e da classificação, o clustering não exige rótulos para os dados. Em vez disso, ele procura identificar grupos naturais dentro dos dados.
Um dos algoritmos mais populares para clustering é o K-means, que tenta dividir um conjunto de dados em clusters com base em suas características. O K-means é amplamente utilizado em segmentação de clientes, análise de mercados e detecção de anomalias.
Aqui está um exemplo simples de como aplicar o K-means para agrupar dados:
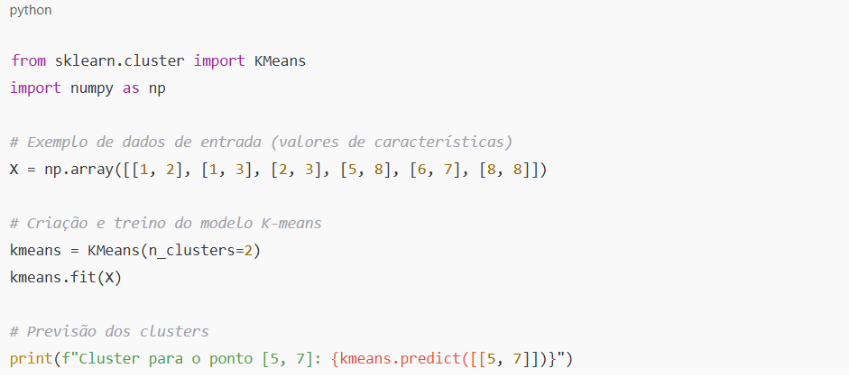
O K-means pode ser ajustado para gerar o número de clusters desejado, permitindo que você aplique a técnica a uma variedade de cenários. Por exemplo, no setor de marketing, você pode usar clustering para identificar diferentes grupos de consumidores, permitindo campanhas mais personalizadas.
A análise preditiva com Python oferece soluções poderosas para prever o futuro e melhorar decisões baseadas em dados. Ao dominar técnicas como regressão, classificação e clustering, você pode extrair insights e aplicar soluções eficazes para seus desafios. Essas técnicas são fundamentais em setores como marketing, finanças, saúde e muitos outros, ajudando empresas a tomar decisões mais informadas e a antecipar tendências.
Se você deseja aprender a aplicar essas técnicas de maneira mais aprofundada e prática, inscreva-se no curso de Análise de Dados com Python até 10/11 e dê o próximo passo para transformar sua carreira!